


CoolWP: Jupyter Notebook
Jupyter Notebook can be accessed by selecting it from the drop-down list under the Development section in the upper menu bar, or by clicking the Jupyter Notebook icon on the dashboard.
|
|---|
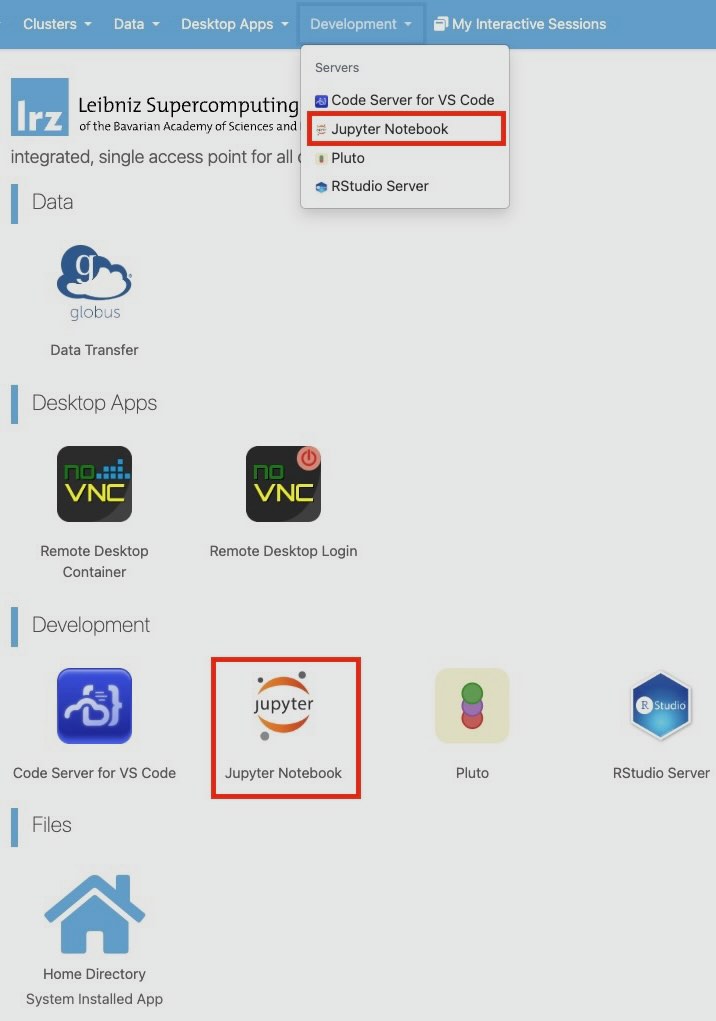
After clicking Jupyter Notebook from the panel, you will find yourself on an overview page providing important information about the resources you want to use. Before you can launch Jupyter Notebook, you must provide some information about the resources you want to use.
|
|---|
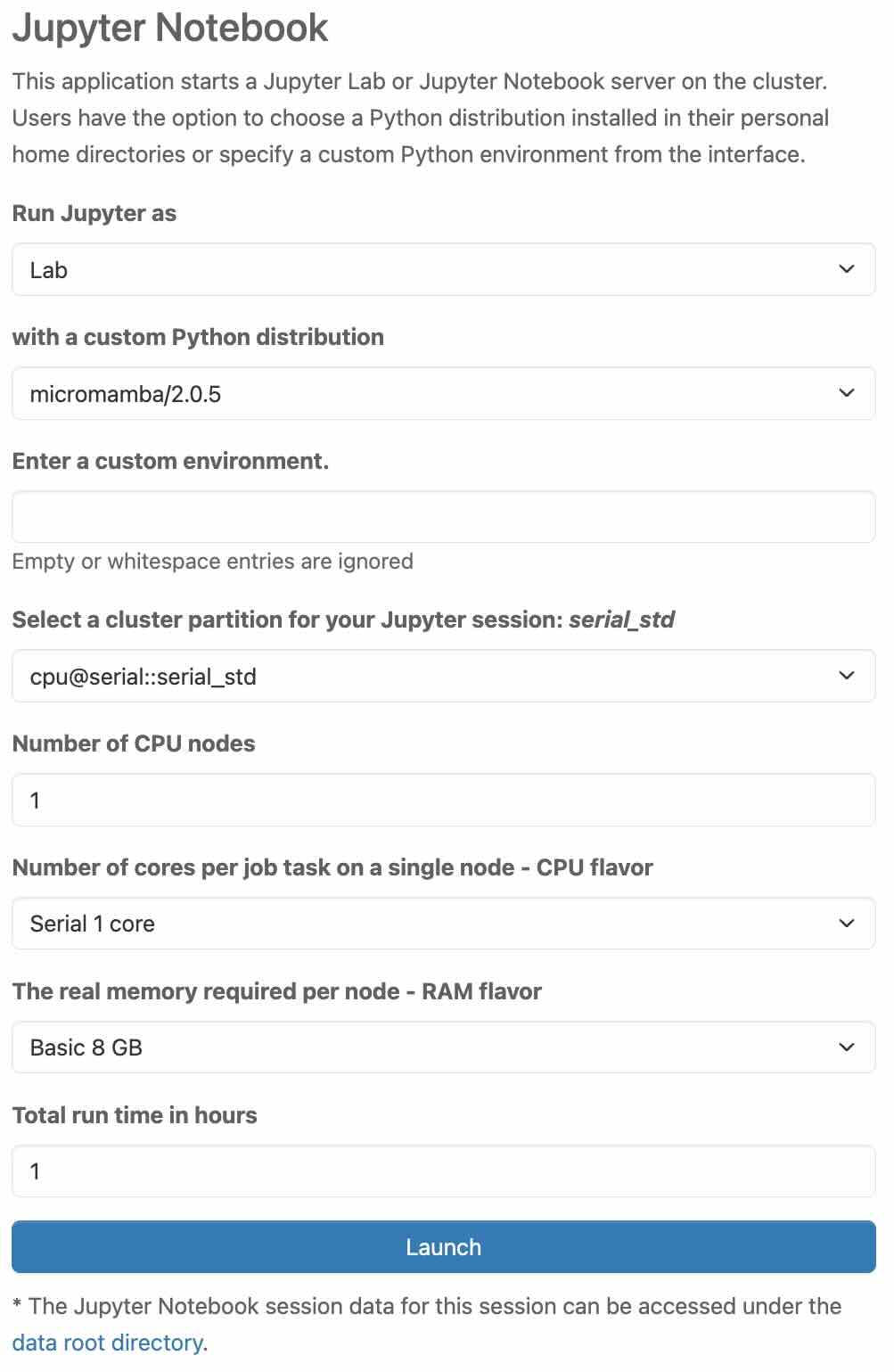
Run Jupyter as
In this section, you choose how to run Jupyter. You can run Jupyter as either “Lab” or “Notebook”.
|
|---|
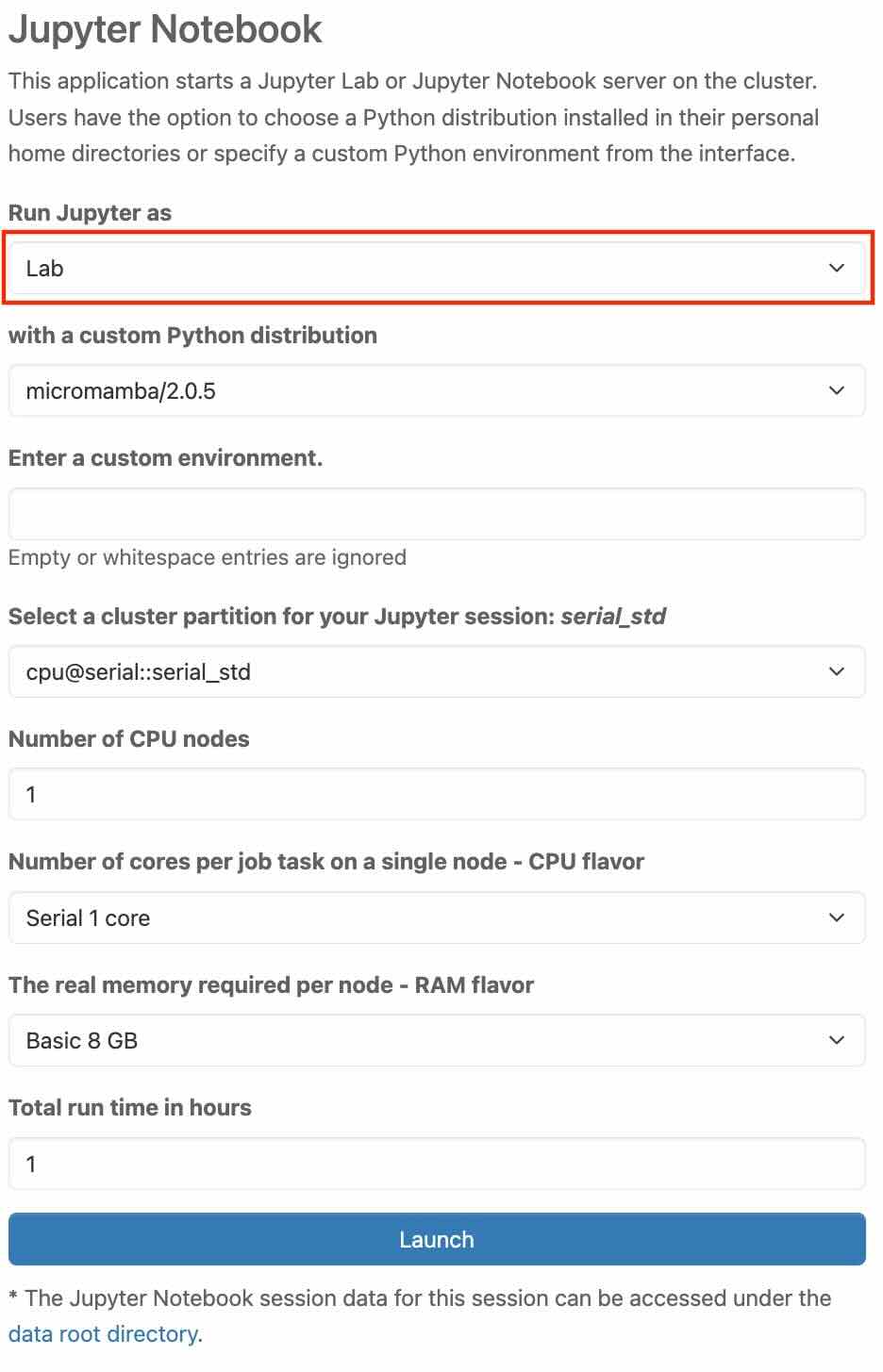
In the "with a custom Python distribution" tab, you need to choose a Python distribution from a list of predefined resource profiles. Currently, a Micromamba-based environment with a minimal set of essential Python packages, including Dask and PySTAC, is supported.
|
|---|
In the "Enter a custom environment", you have the possibility to enter the name (or path) of your environment that you previously created in your home folder. For new environment creation, we strongly recommend using Micromamba over Conda. Micromamba acts as a direct substitute for Conda (replace 'conda' with 'micromamba' in commands) while providing significantly faster installation, especially for complex environments. It utilizes the conda-forge repository, granting access to all available conda-forge packages.
|
|---|
Select a cluster partition for your Jupyter session
In this section, you choose a cluster partition from a list of predefined resource profiles. Select a cluster partition based on your requirements. Further information can be found under Job Processing in the Linux-Cluster documentation.
|
|---|
Number of CPU nodes
You enter the number of CPU nodes in this section. This refers to the number of nodes allocated for a job in the cluster. You can check the availability of nodes and find further information on Job Processing in the Linux-Cluster documentation.
|
|---|
Number of cores per job task on a single node - CPU flavor
In this section, you choose from a list of predefined resource profiles. Each profile defines the number of cores per job task. It tells you how many CPU cores each task of your job will use on one node in the cluster, and what type of CPU (flavor) you want to use. If you need a different number of cores per job task, you have the option to do that as well with "Custom".
|
|---|
In the tab, scroll to the bottom and select “Custom”.
|
|---|
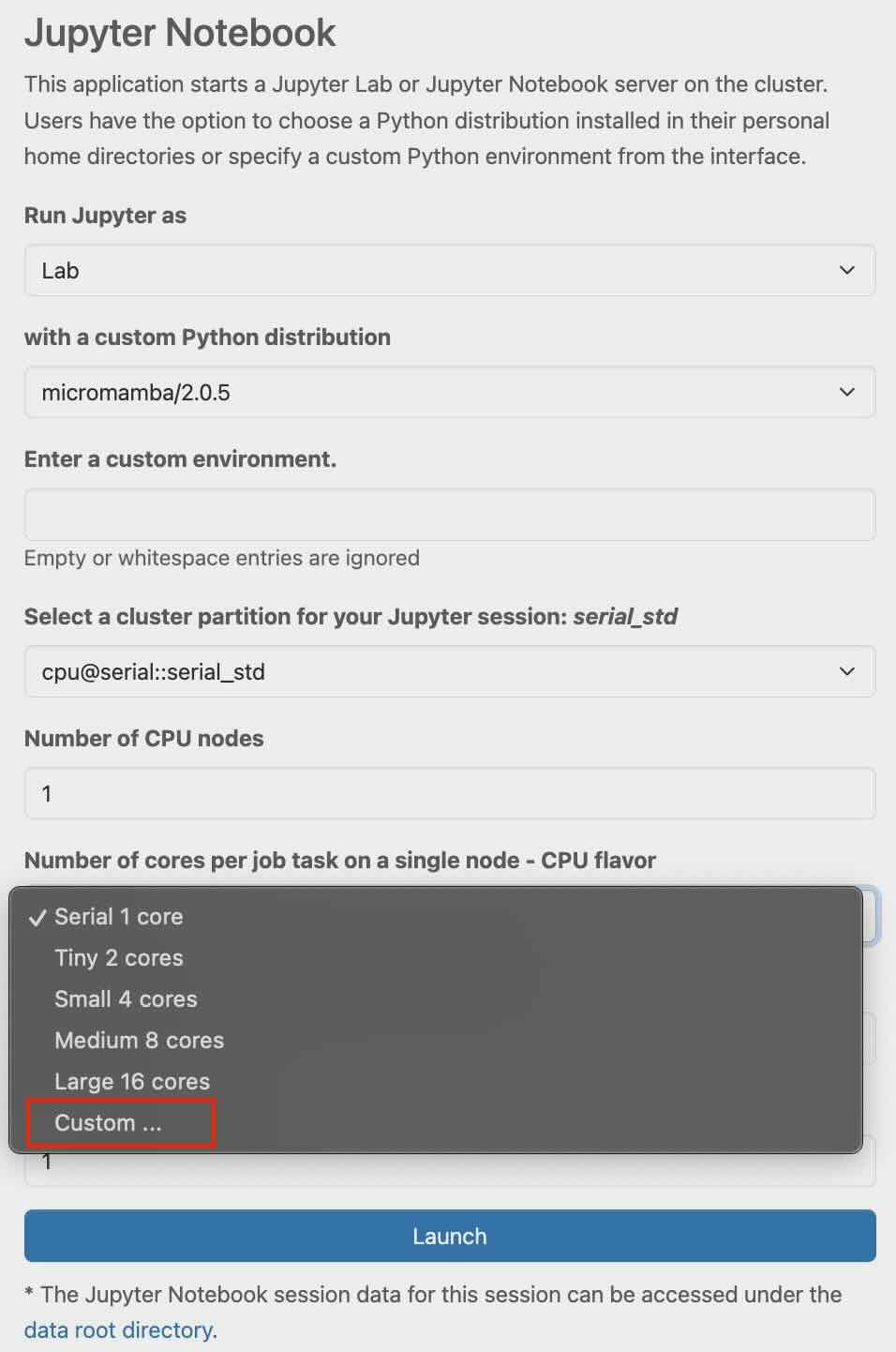
In the "value" tab, you can increase or decrease the custom core number. Further information can be found under Job Processing in the Linux-Cluster documentation.
|
|---|
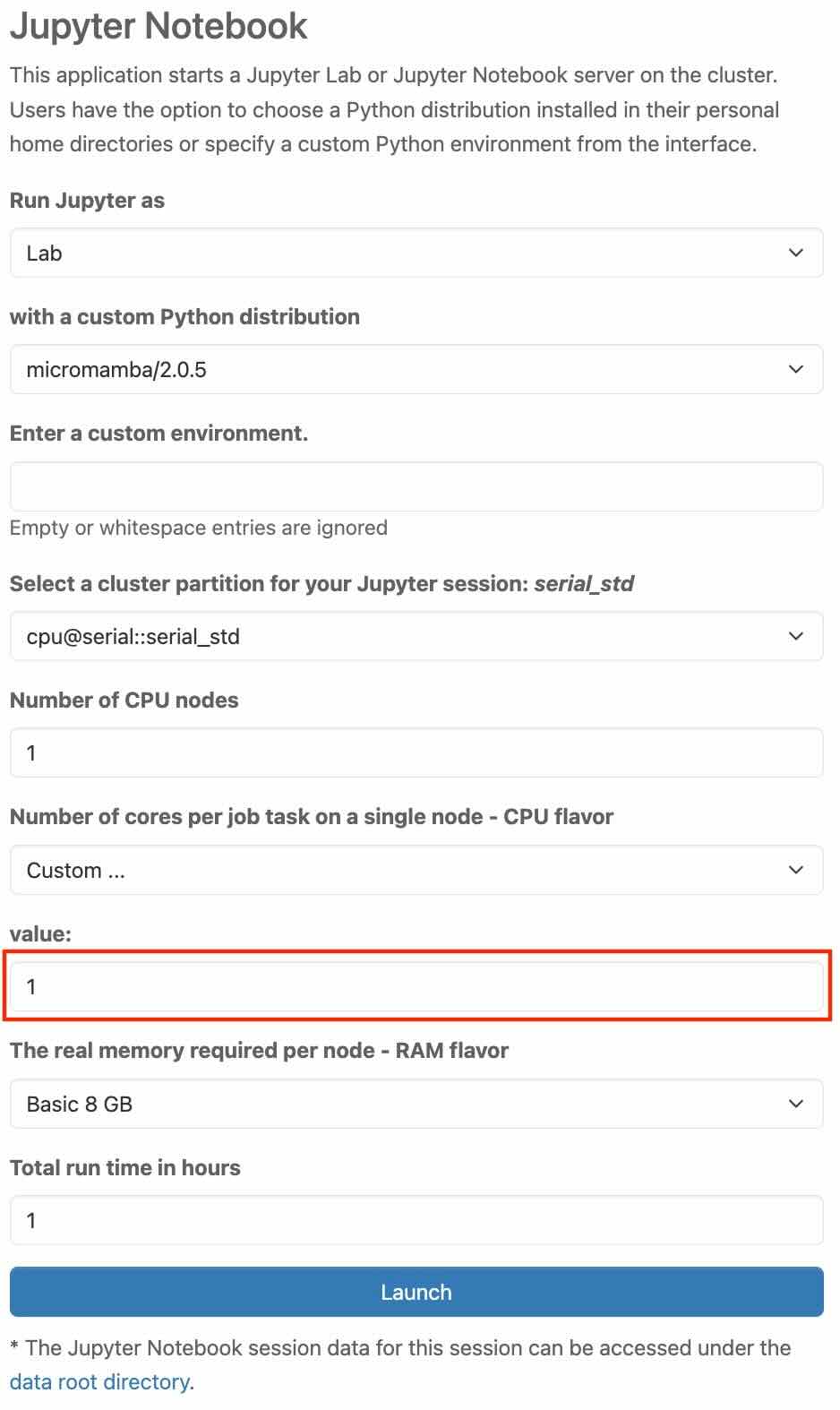
The real memory required per node - RAM flavor
In this section, you choose from a list of predefined resource profiles. Each profile defines the memory per node. It essentially defines how much memory the job needs to function properly on a specific node. If you need a different amount of memory per node, you have the option to do that as well with "Custom".
|
|---|
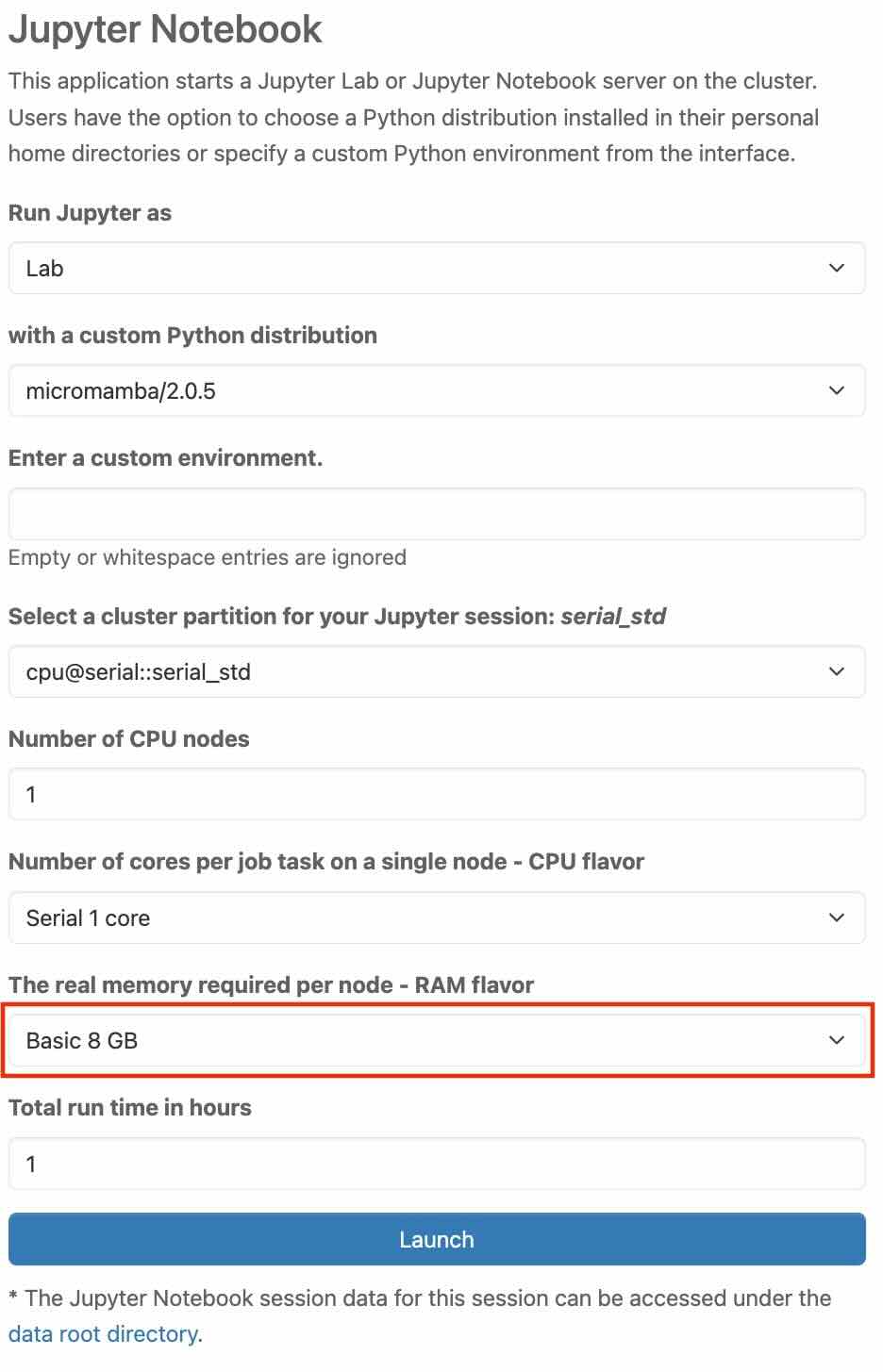
In the tab, scroll to the bottom and select “Custom”.
|
|---|
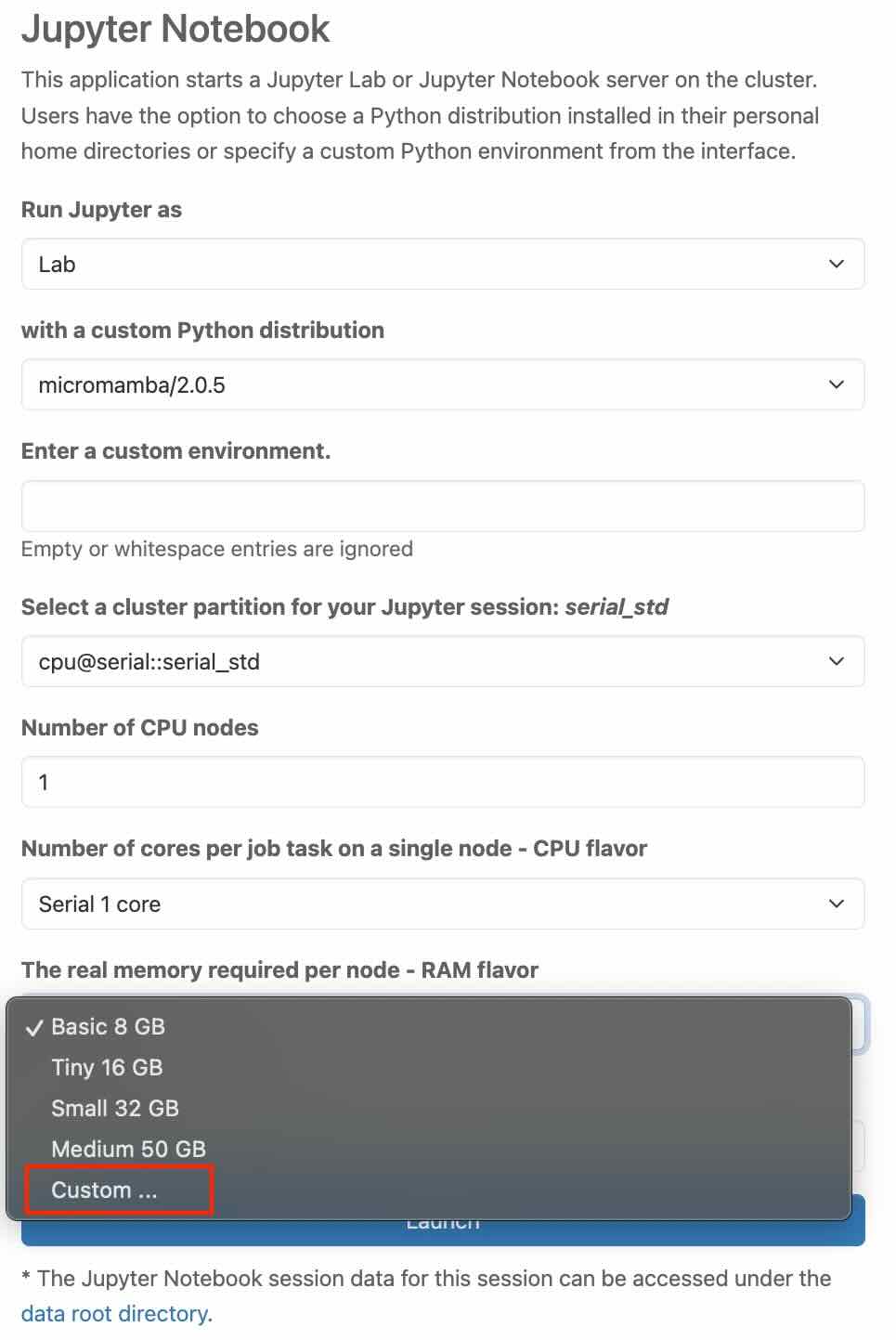
"value in megabytes" tab should appear right below, allowing you to enter the desired custom value. Further information can be found under Job Processing in the Linux-Cluster documentation.
|
|---|
Total run time in hours
In this section, you choose the total runtime in terms of hours.
|
|---|
Launch
Finally, click the “Launch” button located at the bottom of this page to start the application
|
|---|
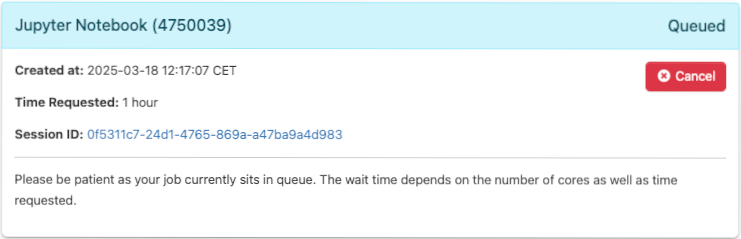
Next, you will be brought to the starting status page of the application. You need to wait as your job will be in the queue. The wait time depends on the number of cores as well as the time requested
|
|---|
Once the resources are allocated, you can click on “Connect to Jupyter“ to log into Jupyter Notebook.
|
|---|
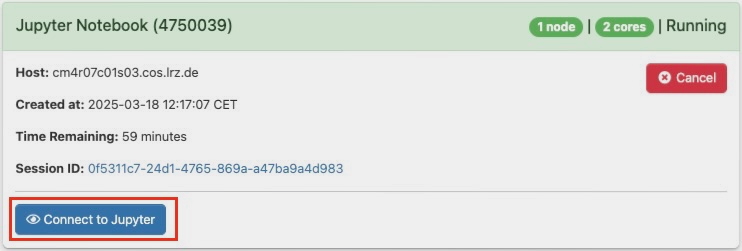
If the connection session expires, click the Connect to Jupyter button to restore access.