


SLURM Workload Manager
List of SLURM commands
The batch system at LRZ is the open-source workload manager SLURM (Simple Linux Utility for Resource management). You must submit a job script to SLURM, which will find and allocate the resources required for your job (e.g. the compute nodes to run your job on). The following table provides an overview of SLURM commands used to submit and manage jobs; on the system, a man page is also supplied for each command.
| Command | Functionality |
|---|---|
| sbatch | submit a job script |
| salloc | create an interactive SLURM shell. |
| srun | execute argument command on the resources assigned to a job. Note: must be executed inside an active job (script or interactive environment); in most cases, using mpiexec (which in turn uses srun for startup) is the preferred alternative. |
| squeue | print table of submitted jobs and their state. Note: non-privileged users can only see their own jobs. |
| sinfo | provide overview of cluster status |
| scontrol | query and modify SLURM state |
| sview | GUI for viewing and managing resources and jobs (see below) |
SLURM is deployed on both the SuperMUC-NG system and the Linux Clusters. For most commands on the Linux Clusters, it is necessary to supply a -M or --cluster= option that specifies for which (sub)cluster the command applies.
sbatch Command / #SBATCH option
Batch job options and resources can be given as command line switches to sbatch (in which case they override script-provided values), or they can be embedded into a SLURM job script as a comment line of the form
#SBATCH <option>=<value>
Examples / How to set up jobs
Job setup for SuperMUC-NG
Job setup for the Linux-Cluster
General options (Shell, Execution Path, Mail, Output etc.)
Note: specifying environment variables in the command section of a SLURM job is not supported.
SLURM option | Functionality | Remarks |
|---|---|---|
-D <directory> | Start job in specified directory. | If this is not specified, the working directory at submission time will be the starting directory of the job. If the specified directory does not exist, the job will not run. |
--mail-user=<mail_addr> | User's e-mail address. | Please use a valid e-mail address so that LRZ can contact you in case of any problems. It is preferred to be used with --mail-type=NONE, see below. |
--mail-type=[BEGIN|END|FAIL|REQUEUE|ALL|NONE] | Batch system sends e-mail when [starting|ending|aborting|requeuing] job. | If ALL is specified, each state change will produce a mail. If NONE is specified, no mails will be sent out. |
-J <req_name> | Name of batch request. | Default is the name of the script, or "sbatch" if the script is read from standard input. Please do not use more than 10 characters here! |
-o <filename> | write standard output to specified file. | LRZ recommends specifying the full path name. Default value is slurm-%j.out, where %j stands for the job ID. Apart from %j, the output specification can also contain %N, which is replaced by the master node name the job is initiated on. You can also specify an absolute or relative directory in the filename. However, the directory must exist, otherwise the job will not run. |
--export=NONE | exports designated environment variables into job script | Please use with care: It is recommended to specify NONE and load all needed environment modules in the script. Conversely, if you use "ALL", it is probably a good idea to not load the module environment via /etc/profile.d/modules.sh in the script section. If only the name of a variable is specified, the existing value is used in the SLURM script at run time. For more than one variable, a comma-separated list must be specified. Example: |
Job Control, Limits and Resource Requirements
SLURM option | Functionality | Remarks |
|---|---|---|
--hold | batch request is kept in User Hold (meaning it is queued but not initiated, because its priority is set to zero) | A held job can be released using scontrol to reset its priority (e.g. "scontrol update jobid=<id> priority=1". |
--time=x:y:z | specify limit for job run time as x hours y minutes z seconds. All three fields must be provided. | This is recommended if you want an improved chance of putting a short or medium-length parallel job through the system using the backfill mechanism of the SLURM scheduler. The maximum run time value imposed by LRZ cannot be exceeded using this option. |
--mem=<memory in MByte> | explicit memory requirement on a per-node basis | The total memory available for the job will be the number of nodes multiplied with the --mem value. For serial jobs, please always specify --mem. Reason: If you only need a small amount of memory, the total job throughput of the cluster may be considerably improved. |
| --nodes=<number>[-<number>] | range for number of nodes to be used | Only for parallel jobs. A range can be specified. |
| --ntasks=<number> | number of (MPI) tasks to be started | by default the number of allocated nodes is equal to the number of tasks divided by the number of physical cores in one node. Only for parallel jobs |
| --ntasks-per-core=<number> | number of MPI tasks assigned to a physical core | This can be used to overcommit resources. Specifying this will normally be only useful on a system with hyperthreaded cores and sufficient memory per core. Should only be specified if --ntasks is used. |
| --ntasks-per-node=<number> | number of MPI tasks assigned to a node | This can be used to overcommit resources. Specifying this will normally be only useful on a system with hyperthreaded cores and sufficient memory per core. Should only be specified if --ntasks is used. |
| --cpus-per-task=<number> | assign a number of virtual CPUs to each started task | this can be specified if either the per-task memory requirement is very large, or if a hybrid (e.g., MPI+OpenMP) program should be run; in the latter case, the number specified should correspond to OMP_NUM_THREADS. |
| --overcommit | Overcommit resources. | |
--requeue / --no-requeue | Identifies the ability of a job to be rerun or not in case of a node failure. If the switch --no-requeue is set, the job will not be rerun. | Default is --requeue |
| --clusters=[all | cluster_name] | specify a cluster to inspect or submit to. You can also use the -M option (with the same modifiers) instead. | Please use this option in scripted batch jobs. A full list of available clusters is provided via sinfo --clusters=all or sinfo -M all |
--partition=<partition_name> | Select the SLURM partition in which the job shall be executed. | Each SLURM cluster contains one or more partitions (with possibly different resource settings) from which a suitable one should be selected by name. |
--dependency=<dependency_list> | Defer start of job until dependency conditions are fulfilled. The dependency list may be one (or more, via a comma separated list) of the following: after:job_id[:job_id ...] (start up once specified jobs have started execution) afterany:job_id[:job_id ...] (start up once specified jobs have terminated) afternotok:job_id[:job_id ...] (start up once specified jobs have terminated with a failure) afterok:job_id[:job_id ...] (start up once specified jobs have terminated successfully) singleton (start up once any previously submitted job with the same name and job user has terminated) | Example: the command sbatch --dependency=afterok:3712,3722 ./myjob.cmd will put a job into the queue that will only start if the jobs with ID 3712 and 3722 in the same SLURM cluster have successfully completed. These jobs may even belong to a different user. |
| --cpu-freq=<value> | Specify the core frequency with which a job should execute. The form the value takes is p1[-p2[:p3]] Please consult the sbatch man page for details. | Example: issuing the command sbatch --cpu-freq=1100 ./myjob.cmd will execute the job at 1.1 GHz core frequency if this is supported. Note: unsupported settings will generate an error message, but the job will execute anyway at some other setting. |
| -C (or --constraint=) | Issue a feature request on the nodes of job | Available features depend on the cluster used. Only one -C option should be supplied, but a comma-separated list of entries can be given as an argument. |
Environment Variables
The environment at submission time is exported into the job for interactive jobs, and also into scripted jobs if the --export=ALL option is specified.
The following additional, SLURM-specific variables are available inside a job:
| SLURM_JOBID | A unique job identifier assigned by SLURM. The jobname set by -N. |
| SLURM_JOB_NODELIST | String containing a coded version of the list of nodes assigned to the job |
| SLURM_JOB_NUM_NODES | The number of compute nodes assigned to the parallel job. |
| SLURM_NTASKS_PER_NODE | The number of tasks to start per node |
| SLURM_NTASKS | The total number of tasks available for the job |
This list is quite incomplete. Please consult the SLURM man pages for more information.
SLURM Exit Codes
When a signal was responsible for a job or step's termination, the signal number will be displayed after the exit code, delineated by a colon(:).
Slurm displays a job's exit code in the output of the scontrol show job and the sview utility. Slurm displays job step exit codes in the output of the scontrol show step and the sview utility.
- For sbatch jobs, the exit code that is captured is the output of the batch script.
- For salloc jobs, the exit code will be the return value of the exit call that terminates the salloc session.
- For srun, the exit code will be the return value of the command that srun executes.
- Exit codes triggered by the user application depend on specific compilers, e.g. List of Intel Fortran Run-Time Error Messages
Details about: SLURM exit codes.
A GUI for job management
The command sview is available to inspect and modify jobs via a graphical user interface:
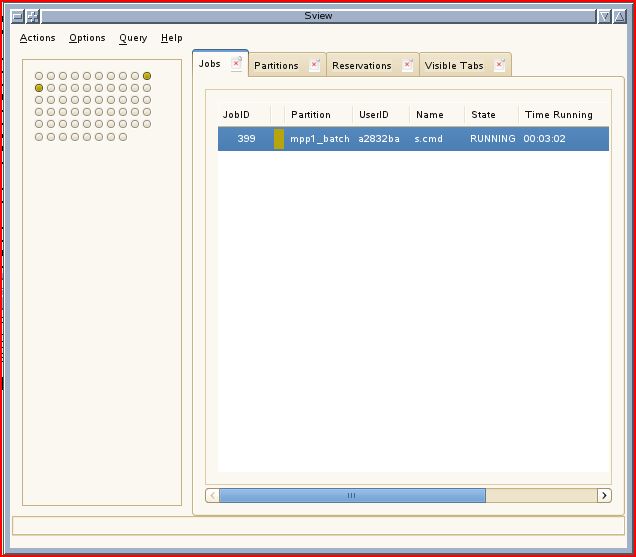
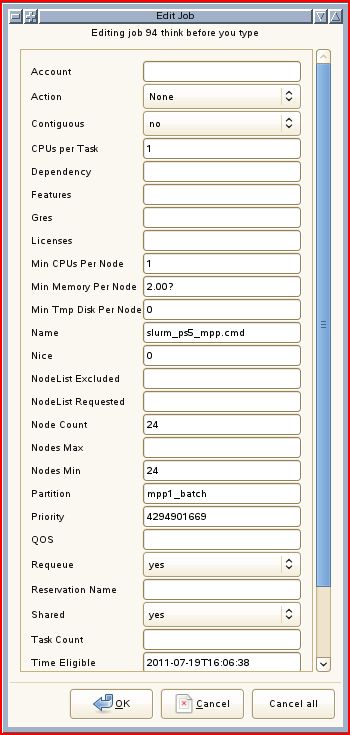
- To identify your jobs among the many ones in the list, select either the "specific user's jobs" or the "job ID" item from the menu "Actions Y Search"
- By right-clicking on a job of yours and selecting "Edit job" in the context menu, you can obtain a window which allows to modify the job settings. Please be careful about committing your changes.