


Code Modernization Projects
The Astro-Lab engages in code modernization projects fulfilling the specifications for high-level support in the Gauss Centre for Supercomputing.
Hover pointer over images to show descriptions.
Recent Highlights
GPU-offloading and Parallelisation of Athenak (2024+)
Astro-Lab members: Sajad Azizi, Salvatore Cielo
AthenaK is an open-source, performance-portable C++ code for astrophysical fluid dynamics, magnetohydrodynamics and numerical relativity, based on the Athena++ AMR framework and implemented using the Kokkos programming model. It supports Newtonian, special relativistic and general relativistic (magneto)hydrodynamics, GR radiation transport, tracer and test particles, as well as fully dynamical spacetimes via a numerical relativity module. GitHub+1
Here we show the preliminary results concerning the parallelisation
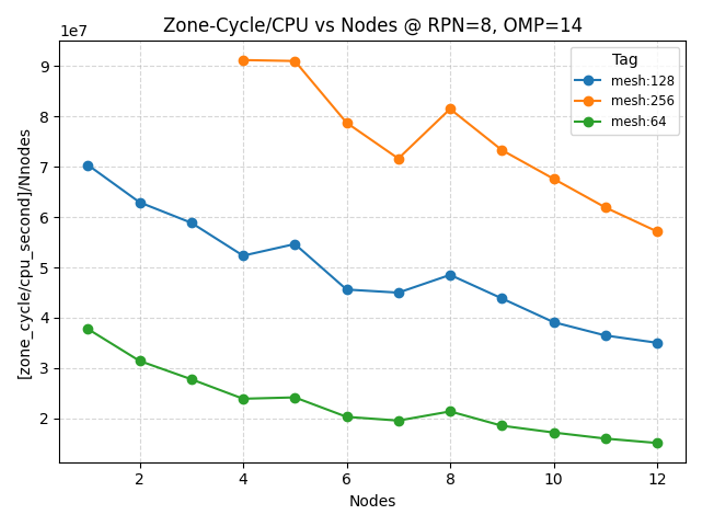
References and impact:
The AthenaK framework and its performance-portable design are presented in AthenaK: A Performance-Portable Version of the Athena++ AMR Framework (Stone et al., 2024). arXiv
AthenaK is already being used for cutting-edge applications in numerical relativity and multimessenger astrophysics, e.g. AthenaK simulations of the binary black hole merger GW150914 (Radice et al., 2025). arXiv
1.2. GPU-offloading and Parallelisation of GaPSE.jl (2024+)
Astro-Lab members: Matteo Foglieni, Salvatore Cielo
GaPSE.jl is a open source Julia code for cosmological computations concerning General Relativistic effects. We are working on the parallelisation of the code, exploiting the KernelAbstraction.jl package, which makes the code compatible with multi-threaded CPU and both Intel and NVidia GPUs.
Here we show the preliminary results concerning the parallelisation of the Gravitational Lensing Two-Point Correlation Function. We compare the original serial code and the CPU multi-threaded new version:
References and impact:
- Preliminary results have been published at the conference Relativistic Effects and Novel Observables in Cosmology (Geneve, 9-12 July 2024)
- For the scientific impact of GaPSE.jl, see Large Scale Limit of the Observed Galaxy Power Spectrum (2023) and The power spectrum of luminosity distance fluctuations in General Relativity (2024)
1.3. Optimization of the RAMSES code
Astro-Lab members: Salvatore Cielo, Margarita Egelhofer
Application partners: Jenny Sorce (CRIStal, Lille, FR - IAS, Orsay - FR, AIP, Potsdam, DE)
The RAMSES code is among the most used MPI-parallel, adaptive mesh codes in Astrophysics. We set up to improve the CPU scaling, which was suffering above a few hundreds of MPI ranks. The code was profiled with APS and VTune from Intel oneAPI, thanks to which several issues, all of comparable entity, were identified:
- Usage of dated compilers and options
- Load Imbalance of medium entity, luckily mostly localized to clear kernels:
particles,hydro - godunov,hydro - rev ghostzones - MPI inefficiencies, especially
- collective calls such as
MPI_Allreducein kernels such assink_particlesandagn_feedback - and
- collective calls such as
- Inefficient memory layout of the main data, forcing strided memory access
- Large on-the-fly memory allocations that significantly expanded the memory footprint

A number of interventions were devised to address these issues. The successful ones have been implemented in code patches:
- Parallel Makefile options have been added, largely speeding up compilation
- Several compilers were tested, with modern Intel compilers yielding the best performance
- MPI calls were optimized with moderate gains by swapping blocking and non-blocking variants, although load imbalance still results in long MPI wait times
- Profiling instrumentation and timers were added for more granular further profiling
- The code version was updated to include Light AMR code changes by third party RAMSES developers.
Albeit the performance remained invariant, this reduced the memory footprint
Unfortunately, other efforts did not succeed:
- A memory layout swap in a nested Fortran code was too large a change to implement, albeit it has been notified to the main developers
- The introduction of an OpenMP threading layer in targeted region (e.g. aimed at reducing load imbalance) did not speedup the code significantly,
due to memory access limitations. The integration of existing 3rd parties OpenMP implementations could have better success. - A restart patch allowing to change the number of MPI tasks would be a must for larger runs; efforts are being carried out by other parties, so it was postponed
 for the developed patches (the lower, the better). Median, 1st/3rd quartile and 10th/90th percentile of 20 measures")
References:
- GCS report: Researchers Use the Power of SuperMUC-NG to Map Our Near Universe
- Optimized version is hosted on LRZ gitlab servers, may be pushed to user base
- Global_Timing.pdf
DPEcho: General Relativity with SYCL for the 2020s and beyond
AstroLab contact: Salvatore Cielo
Application partners: Alexander Pöppl (Intel Corporation, Munich), Luca Del Zanna (Università degli Studi di Firenze), Matteo Bugli (Università degli Studi di Torino)
Numerical sciences are experiencing a renaissance thanks to GPUs and heterogeneous computing, which open for simulations a quantitatively and qualitatively larger class of problems, albeit at the cost of code complexity. The SYCL programming language offers a standard approach to heterogeneity that is scalable, portable, and open.
After ECHO-3DHPC, code for General-Relativistic Magneto-Hydrodynamycs (GR-MHD), written in Fortran with hybrid parallelism via MPI+OpenMP, here we introduce DPEcho, the MPI+SYCL porting of Echo, used to model instabilities, turbulence, propagation of waves, stellar winds and magnetospheres, and astrophysical processes around Black Holes. It supports classic and relativistic MHD, both in Minkowski or any coded GR metric. The public version of DPEcho is available on GitHub under an Apache II license.
DPEcho revolves around SYCL device-centric constructs (parallel_for, Unified Shared Memory, ...) in order to minimize data transfer and use the devices at best.
// Initialize the SYCL device and queue
sycl::gpu_selector sDev; sycl::queue qDev(sDev);
// Allocate main variables with USM
double *v[VAR_NUM], *f[VAR_NUM], [...];
for (int i=0; i < VAR_NUM; ++i) {
// Primitives and fluxes for each variable
v[i] = malloc_device<double>(grid.numCells, qDev);
f[i] = malloc_device<double>(grid.numCells, qDev);
[...]
}
We present a scaling comparison of DPEcho versus the baseline ECHO, running the same problem setup. We first conduct a weak scaling test on the Intel Xeon 8174 nodes of SuperMUC-NG at the Leibniz-Rechenzentrum (left). We observe essentially flawless scaling up to 16 nodes, and performance up to 4x higher than the baseline version. The reduced memory footprint of DPEcho allowed the placement of 3843 cells per MPI task, instead of 1923. The inclusion of the Intel® Iris® Xe MAX Graphics (right) increases performance up to 7x, surpassing even non-accelerated HPC hardware. This is a testament to the superior portability and efficiency of SYCL code, making the most efficient use of all classes of hardware.
 and DPEcho.")
More resources on DPEcho:
- Intel feature articles on Intel Developer Zone and Parallel Univers Magazine
- Open source code entries on GitHub and Zenodo
OpenMP GPU offload of the cosmoloical simulation code OPENGADGET3
AstroLab contact: Margarita Egelhofer, Salvatore Cielo
Project partner: Nitya Hariharan (Intel)
OPENGADGET3 is a code for cosmological N-body/SPH simulations on massively parallel computers with distributed and/or shared memory. OPENGADGET3 uses an explicit communication model that is implemented with the standardized MPI communication interface and is fully threaded with OpenMP. OPENGADGET3 computes gravitational forces with a hierarchical tree algorithm (optionally in combination with a particle-mesh scheme for long-range gravitational forces) and represents fluids by means of smoothed particle hydrodynamics (SPH). The code can be used for studies of isolated systems, or for simulations that include the cosmological expansion of space, both with or without periodic boundary conditions. In all these types of simulations, OPENGADGET3 follows the evolution of a self-gravitating collisionless N-body system, and allows gas dynamics to be optionally included. Both the force computation and the time stepping of OPENGADGET3 are fully adaptive, with a dynamic range which is, in principle, unlimited.
Before this optimization started, parts of the computations in OPENGADGET3 could already be offloaded to a GPU using the OpenACC standard. However, not all hardware providers support the OpenACC standard. Nitya Harihan from Intel began an implementation of OpenMP GPU offload. The gravity computation as well as the primary density can now be offloaded this way. Still in progress are the secondary density and other hydrodynamic functions offload.
Other projects
AstroLab contact: Jonathan Coles, Salvatore Cielo
Application partner: Aura Oberja (Universitäts-Sternwarte München, LMU), Tobias Buck (Leibniz-Institut für Astrophysik Potsdam)
Project partner: Christoph Pospiech (Lenovo)
Gasoline2 is a smoother particle hydrodynamics code, built on top of the N-body code PKDGRAV. It is used for cosmological galaxy formation simulation, such as the NIHAO project (Wang et al. 2015). The follow up project, NIHAO2 -- which was granted a total of 20 Mio-CPU hours on SuperMUC-NG at LRZ --, aims to construct a large library of high resolution galaxies at redshift (𝑧) > 3, covering a mass range from massive dwarfs to high-𝑧 quasar host galaxies, while also improving on thermal balance, radiation and chemical enrichment physics. These simulations will help to answer some of the open questions in galaxy formation and to interpret new observational measurements from the James Webb Space Telescope, and the future Athena X-ray Observatory.
The modernization project of Gasoline2_LAC (Gasoline 2 with Local Photoionization Feedback (Obreja et al. 2019), Amiga halo finder for black hole seeding and accretion feedback (Blank et al. 2019) and Chemical enrichment (Buck et al. 2021)) had three initial goals: 1) ensure that the code compiles and runs without errors, 2) lower the memory footprint, and 3) improve the code scaling. After starting the project, we also decided to work on improving the accuracy of the radiation fields needed by the Local Photoionization Feedback. As the radiation fluxes were computing on the tree at the same time with the accelerations, the most natural step forward was to use a higher order (the initial code was only zero-order) for the radiation fields’ multipoles.
The speedups of all kernels involved in the optimization are shown in the left figure. The Gravity and GravTree components present the most significant speedups (∼20% and >80%, respectively), leading to an overall ~25% improvement. The right figure shows a single-node scaling test with the g2.19e11 test case (halo mass ∼2 × 1011 M⊙ at redshift 0), featuring the time to solution of individual kernels. While the scaling, on this test case, deviates still early from the ideal (likely due to load imbalance), the optimized performance is still > 25% better than the initial. The figure is also a guide for for finding bottlenecks in view of future optimization projects. Due to its improved scaling, GravTree is no more the top-pressure bottleneck.
We are now able to run simulations more reliably, use more MPI ranks per node with less performance loss, and reach increased accuracy in the radiation fields thanks to the new physics modules. This opens to the possibility of running higher-resolution galaxies with the same resources, or to increase the number of galaxies we can simulate with a given computational budget, for both the LRZ allocation, and in the framework of NIHAO2.

The full report of the optimization project is available here: Gasoline_optimization_report.pdf
AstroLab contact: Luigi Iapichino, Salvatore Cielo
Application partner: Oliver Porth (Uni Amsterdam), Hector Olivares (Radboud Univ.)
Project partner: Fabio Baruffa (Intel), Anupam Karmakar (Lenovo)
BHAC (the Black Hole Accretion Code) is a multidimensional general relativistic magnetohydrodynamics code based on the MPI-AMRVAC framework. BHAC solves the equations of ideal general relativistic magnetohydrodynamics in one, two or three dimensions on arbitrary stationary space-times, using an efficient block based approach.
BHAC has proven efficient scaling up to ~200 compute node in pure MPI. The hybrid parallelization scheme with OpenMP introduced by the developers could successfully extend scaling up to ~1600 nodes, at the cost of a drop in efficiency to 40% or 65% (with 4 or 8 threads per node, respectively). The main goal for the modernization of the code is thus to check, profile and optimize the OpenMP implementation and node-level performance, including vectorization and memory access.
Early tests revealed a rather high degree of vectorization, though with some room for improvement as the code contains a mix of compute-bound and memory-bound (the slight majority) kernels.
VTune’s threading analysis exposed an OpenMP imbalance, addressed by adding dynamic scheduling to the loops with significant workload. This yielded an average performance improvement of ∼ 5%. Yet the same analysis identified the main bottleneck as large serial code blocks in the ghost-cell exchange. Restructuring of the code allowed to fully OpenMP-parallelize this section of the code, which led to an average performance increase of 27% compared to the initial code.
At the end of the project, the hybrid implementation is capable to efficiently utilize over 30 000 cores, allowing to study large scale problems. The improvements made through in the AstroLab project are already merged into the staging branch of BHAC and will become part of the next public release.

The full report of the optimization project is available here: AstroLab_BHAC.pdf
AstroLab contact: Luigi Iapichino, Salvatore Cielo
Application partners: Elias Most, Jens Papenfort (Institute for Theoretical Physics, Univ. Frankfurt)
Project partner: Fabio Baruffa (Intel)
The gravitational waves (GW) events produced by collision and merging of compact objects such as neutron stars have recently been observed by the LIGO network for the first time. Understanding the observed electro-magnetic counterparts of these events can grant a complete, multi-messenger view of these extreme phenomena, but requires extensive numerical work to include the strong magnetic fields and turbulence involved. As these require extremely high resolution and computing power, scaling parallel simulation codes to large core units is a must.
The GReX code has successfully run simulations of neutron star mergers up to 32 k cores on SuperMUC-NG, while taking large advantage of the SIMD capabilities of modern CPUs. Scaling to extreme core counts (> 100k) is however required to leverage on the power of the coming Exascale Supercomputers. During the optimization project with the Astro-Lab, we identified the main bottlenecks in load balancing and communication when using a large number of AMR grids with many cells. After a detailed characterization through Application Performance Snapshot and Intel Trace Analyzer and Collector, we performed several node-level scaling tests and investigated the effect of local grid tiling on the performance up to 256 nodes. However the best results were obtained by an by rewriting the way the code exchanges ghost cells around grids via MPI (see full report below).
Thus we were able to achieve a scaling close to ideal up to about 50 k cores during the LRZ Extreme Scaling Workshop. The performance degrades significanlty around 70 k cores, however succesful runs with stil satisfactory perfomance were now possible up to about 150 k cores. The reason for this loss is not yet completely understood, but it is likely associated with a different load-balancing at intermediate core counts for the specific problem setup, and will be ivestigated in the future. Both parties were very satisfied with the achieved optimization and look forward to further collaborations.
 .
.
The full report of the optimization project is available here: AstroLab_GReX_report.pdf
AstroLab contact: Luigi Iapichino
Application partner: Matteo Bugli (CEA Saclay, France)
Project partner: Fabio Baruffa (Intel)
In this project we improved the parallelization scheme of ECHO-3DHPC, an efficient astrophysical code used in the modelling of relativistic plasmas. With the help of the Intel Software Development Tools, like Fortran compiler and Profile-Guided Optimization (PGO), Intel MPI library, VTune Amplifier and Inspector we have investigated the performance issues and improved the application scalability and the time to solution. The node-level performance is improved by 2.3x and, thanks to the improved threading parallelisation, the hybrid MPI-OpenMP version of the code outperforms the MPI-only, thus lowering the MPI communication overhead.
 for the baseline and optimized code versions.")
More details: see article on Intel Parallel Universe Magazine 34, p. 49.
ArXiv version here.