


Decommissioned HLRB I Hitachi SR8000-F1
aka: Höchstleistungfsrechner in Bayern I, Bundeshöchstleistungsrechner in Bayern I

Hardware
| Number of SMP-Nodes | 168 |
| CPUs per Node | 8 (COMPAS, 9 physical) |
| Number of Processors | 168*8 = 1344 |
| Peak Performance per CPU | 1.5 GFlop/s 1 |
| Peak Performance per Node | 12 GFlop/s1 |
| Peak Performance of the whole System | 2016 GFlop/s1 |
| LINPACK Performance of the whole System | 1645 GFlop/s1 |
| Expected Efficiency (from LRZ Benchmarks) | > 600 GFlop/s1 |
| Performance from main memory (most unfavourable case) | > 244 GFlop/s1 |
Memory per node | 8 GBytes (ca. 6.5 GByte in user space) 4 Nodes with 16 GByte each |
| Memory of the whole system | 1376 GBytes |
| Processor Characteristics Clock Frequency Number of Floatingpoint Registers Number of Integer Registers Data Cache Size DCache Line Size Dache Copy back or Write through DCache set associativness DCache Mappping Bandwidth Registers to L1 DCache relative to frequency relative to compute performance Bandwidth to Memory relative to compute frequency relative to compute performance Instruction Cache ICache set associativness ICache Mapping | 375 MHz 160 (Global:32, Slide:128) 32 128 KB 128 B Write through 4-way direct 12 GByte/s 32 Bytes/cycle 1 DP Word / theor. Flop2 4 GBytes/s 10 Bytes/cycle 1/3 DP Words / theor. Flop2 4 KB 2-way direct |
| Aggregated Disk Storage | 10 TBytes3 |
| Disk storage for HOME-Directories (/home) | 800 GBytes |
| Disk storage for temporary and pseudo-temporary data | 5 TBytes3 |
| Aggregated I/O Bandwidth to /home | > 600 MByte/s |
| AggregatedI/O Bandwidth to temporary data (/tmpxyz, /ptmp) | 2.4 GByte/s |
| Communication bandwidth measured unidirectionally between two nodes (available bidirectionally) using MPI without RDMA using MPI and RDMA hardware | 770 MByte/s 950 MByte/s 1000 MByte/s |
| Communication capacity of the whole system (2 x unidirectional bisection bandwidth) with MPI and RDMA | 2x79=158 GByte/s (Hardware: 2x84 =168 GByte/s) |
1 1 GFlop/s = 1 Giga Floatingpoint operations/second = 1000000000 (1 with 9 Zeros, Giga) Floating Point Operations per second.
2 Machine Balance: Number of Double Precision (64-bit) Words per theoretical possible Floating Point Operation
3 1 TByte = 1TeraByte = 1000 GBytes
System
The innovative architecture of the SR8000-F1
The innovative architecture of the SR8000-F1 enables the usage of the vector programming paradigm and the scalar SMP-Cluster programming paradigm on the same machine. This is achieved by combining eight of the nine superscalar RISC CPUs with 1.5 GFlop/s peak performance into a virtual vector CPU of 12 GFlop/s peak performance. In a traditional vector CPU the vectorized operations are executed by a vector pipe which delivers one or more memory references (e. g. numbers) per cycle to the CPU. On the Hitachi SR8000-F1 the vectorizable operations are either divided among the 8 effectively usable CPUs (``COMPAS'') or specific memory references are loaded into the registers some time before actual use (``PVP''). The advantage of this architecture is that all computing units can be used eightfold, not only the floating point pipes which are usually implemented on traditional vector CPUs. The following two properties of the SR8000-F1 nodes especially contribute to the high efficiency obtained in comparison to RISC systems:
Pseudo-Vector-Processing (PVP)
Hitachi's Extensions to the IBM POWER instruction set which improve the memory bandwidth alleviate this main deficit of RISC-based High Performance Computing. This property, called Pseudo Vector Processing by Hitachi, may be used by the compiler to obtain data either directly from memory via prefetch or via the cache, depending on how the memory references are organized within the code to be compiled.
![]()
The concept of PVP may be illustrated by the following example loop:
DO I=1,N
A(I) = B(I) + C(I)
ENDDO
Without PVP the following operations would be performed within the registers:
![]()
Since the prefetch operations may be executed simultaneously with the floating point operations, one obtains the following picture when making use of PVP:
![]()
Prefetch is not very efficient when the main memory is accessed non-contiguously because the prefetched cache line may contain unnecessary data. To improve this situation the pre-load mechanism was implemented. Pre-load is efficient even for non-contiguous access, because it transfers element data directly to the registers. By making use of the slide-window technique the logical register numbers are mapped to physical register numbers according to the principles demonstrated in the following two figures.
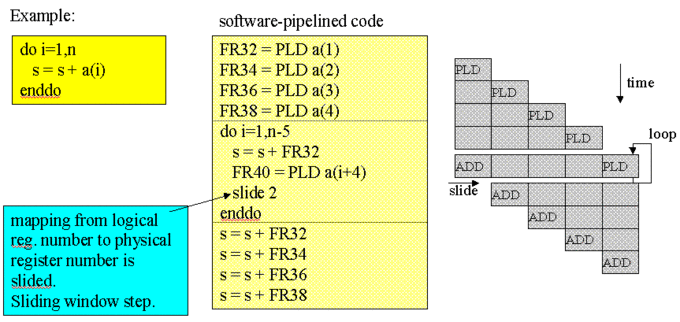
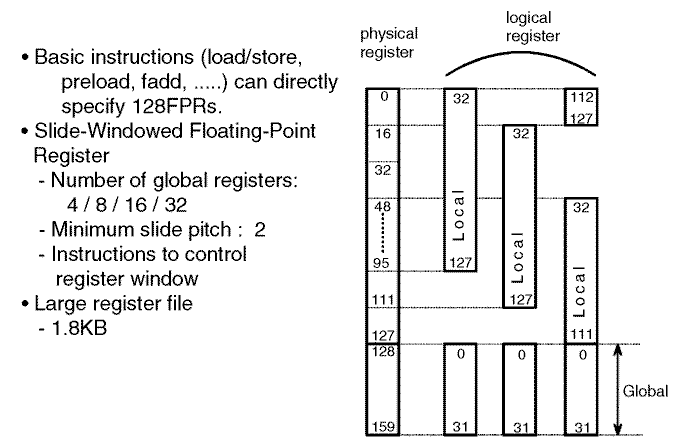
Co-operative Micro Processors in single Address Space (COMPAS)
Co-operative Micro Processors in single Address Space is Hitachi's name for the automatic distribution of computational work of a loop among the 8 CPUs of an SMP node by the compiler (autoparallelization) and the accompanying hardware support for synchronization (e.g., automatic cache synchronization at the beginning and end of a parallel code segment.)
![]()
Of course these properties may also be used by codes which use the nodes as 8-way SMP-nodes via MPI and/or OpenMP. Hence the Hitachi System is not only an option for those 75% of HPC users, who according to a poll within Bavaria, use vectorizable programs to obtain very high performance on this platform, but also for the remaining 25% of users. The price to pay for this flexibility will be long compilation times, at least for the first compiler releases.
A speciality of Hitachi's UNIX Operating Environment HI-UX/MPP is the common file system tree for all nodes, i.e., from the file system point of view one has a Single System Image. By making use of the Striping File Feature (SFF) it is possible to extend file systems across several server nodes in order to achieve high I/O bandwidths for (parallel) access to files, e.g., via MPI-I/O.
Furthermore, it is possible to subdivide the system into partitions, either logically separated subsystems or possibly overlapping partitions for resource allocation to specific jobs. Jobs may be frozen in order to reallocate their resources to other jobs with higher priority.